One of the most requested features for my terminal user interface library tview (now at 8.6K stars, which is still mind-boggling to me) was a multi-line text editor. Before starting to work on this UI component, I collected my users’ requirements for it. They basically boiled down to this:
- A multi-line text editor with optional word wrapping
- Common navigation keybinds: arrow keys, home, end, page up/down, scrolling
- Common editing keybinds: appending/inserting characters, backspace/delete, deleting words/lines/partial lines
- Mouse handling
- Selecting text, deleting/replacing it
- Copy/paste functionality
- Undo/redo
- Proper Unicode handling (e.g. foreign characters and emojis)
Some of these features were not explicitly requested but added by me in anticipation of future requests or complaints. Specifically, undo/redo functionality was mentioned as “not important” by two people. However, it is such a common operation (at least for me it is) when editing text that I was afraid that leaving it out would lead to complaints later. And as we will see, it is not something you can simply patch onto an existing text editor. It has to be baked in from the start.
The “Minor” Parts
Programming the TextArea component was a lot of work and many of its parts were not even added to its main codebase. For example, Unicode handling, layout (monospace character widths), word wrapping, and word boundary detection all needed to go into my other package, github.com/rivo/uniseg, first. That package already implemented Unicode grapheme cluster detection but it needed these other features, too. I spent the first part of a Portugal vacation in the summer of 2022 to add these features to uniseg, mostly in the evenings after a day of surfing or hanging out at the beach.
The second part went into the actual implementation of the text editor, which I’m covering in more detail in this blog post.
My Choice of Data Structure
A common data structure used to implement text editors is the Gap Buffer. The text is split into two parts: the part before the cursor and the part after the cursor. An empty gap (not shown to the user) is kept between those parts. As the cursor moves, individual characters are moved from either end of the gap to the other. When the user enters text, it is simply added to the left side of the gap, reducing its size. It can certainly be made to work with the features I mentioned above — after all, Emacs implements the Gap Buffer — but it seemed to me that implementing undo/redo and copy/paste would not be trivial. I also didn’t like the idea of having to move characters around in memory all the time.
Another common data structure is the Rope. The Rope is a binary tree where each node represents a text segment. The operations you need to implement on the Rope for a text editor include inserting, deleting, splitting, rebalancing, and more. That’s basically where I noped out. I know that a lot of programmers love binary trees. But just imagining debugging a Rope implementation seemed like a nightmare to me.
Finally, the Piece Table also adds elements on top of the text, the so-called “spans”, which reference a continuous block of text in either the original document or the added text. But instead of a tree, it is basically a doubly-linked list. That seemed manageable to me.
Implementing the Piece Table
There is a good article on how to implement a Piece Table (the author calls it “Piece Chain”) and I used many of its ideas, along with some improvements which I will outline here.
We maintain two text buffers: the original text (a fixed string) and the added text (a growing string, implemented as a strings.Builder). Each span in our Piece Table represents a continuous block of text, a substring, in either of these buffers. It stores an offset, i.e. the starting point, and a length. I chose to use negative lengths to indicate that the span refers to the original text and positive lengths to indicate that it refers to the added text in the Builder. We start out with a single span which refers to the entire original text:
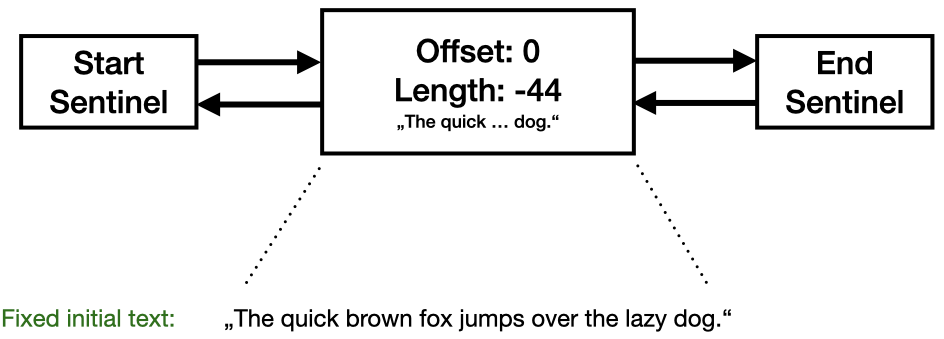
You will notice that our linked list has three elements instead of just one. This idea is taken from the Piece Chains article. Adding dummy elements at the beginning and at the end (we call them “sentinels”) makes dealing with the list a lot easier as we don’t have to handle nil references at the beginning and end of the list. All actual text spans have valid links. And these sentinels never reference any text.
The spans themselves are kept in a span slice (the Go equivalent of an array) with the start sentinel always at index 0 and the end sentinel always at index 1. Because almost all of our operations are on the spans, any location in the current text is now an offset within a specific span. A text location is represented by two numbers: the index of the span in the span slice and the offset within that span. For example, here the location of the cursor is 15 characters into the span at index 2:

If the user now enters text at that cursor position, we split the span at index 2 into two separate spans and insert a new span which references the growing text buffer where the user’s text is stored:

We don’t do this for each individual character, however. If a character adds to the end of the previously inserted/extended span, we can simply grow it, with one exception: We create new spans after each word. That’s because we want to undo word-wise instead of removing/showing all previously entered text at once. (This is a useful behaviour I noticed in editors such as Visual Studio Code.)
You may have noticed that there is no span with index 2 in this picture anymore. It still exists but it is not part of the linked list. The span slice also only grows. We never delete or replace spans because we still need these old spans for undo/redo.
Replace: One Function for Everything
The Piece Chain article talks about three different operations: inserting text, erasing text, and replacing text. It goes on to describe the implementations for each of these operations. My implementation instead reduces all operations to just one function: Replace.
The Replace function deletes a block of text which may span multiple spans and then inserts new text at the same location. If the block to be deleted has a length of 0, it is just an insert. If the new text is an empty string, it is just a delete. But even replacing a larger block of text with another large block of text happens more often than not: Imagine selecting a block of text and replacing it with a “paste from clipboard” operation. In the end, this would just be one call to the Replace function.
The implementation of Replace is a bit more complex and it took a while to get it right. But once I had it, everything else was quite simple. You can check out the code here.
Navigation
One of the downsides of the Piece Table data structure is that it is difficult to jump to specific cursor locations. Moving by one character (e.g. with the left/right arrow) is still simple but vertical movement requires traversal of the linked list. It essentially becomes a linear search forward or backwards at O(n) with n being the size of the span slice. The more a text was edited, the more spans there are and the slower this search becomes. I have yet to see actual usage statistics but I would assume that most editing sessions will result in an acceptable number of spans where the navigation speed is not noticeably affected.
Complicating navigation further is our requirement to implement word-wrapping. The uniseg package gives us a tool to identify possible line breaks and we use that. The layout of the text is described by a line buffer which references the start location (in span space) of each line of text. This is a lazily initialized buffer, that is, we only maintain all visible lines and the ones before it. Lines after the visible lines are only calculated when they are needed. This avoids parsing the entire text when the editor is first displayed. If the user ever jumps from the beginning to the end of the text, however, there is no way around parsing everything.
Undo/Redo
The Piece Table makes undo/redo functionality very simple. We already established above that no spans are ever deleted. All we have to do now is maintain a stack of span pairs embracing a change. An undo/redo operation simply replaces these span pairs.
One downside is that it invalidates the line buffer. There may be ways to optimize rebuilding the line buffer but I didn’t go for that.
Conclusion
All in all, this was a fun coding exercise. Most coding I do is much more mundane than mastering the complexity of a text editor so this was a welcome change. And the editor appears to work well. It’s been available for a year now and there were only a minimal number of bug reports, none of them referring to anything critical.
I’m considering breaking it all out into its own package at some point. This would allow others to write their own text editors in Go without having to jump through the same hoops I did. For example, one may want to add line numbers or syntax highlighting. You could even write an editor for very large files by making the spans reference a file on disk instead of a string in memory.
If there is serious demand for this, I might tackle it one day.